經過昨天介紹的 zeabur 後,現在已經解決 DB server 的問題了,那今天打算基於 postgres SQL 當作我們本系列的 SQL 選擇~
大家還記得吧,因為 ORM 本身要映射 DB ,那同時 prisma 需要支援多種 DB 類型,所以不免俗的需要提供多種 adapter 通知 prisma 要關聯到哪種類型的 DB ,在這邊我們提到一個 keyword Database drivers。
這邊筆者想先提一個有趣東西就是,prisma client 跟 database之前有一層 QUERY ENGINE 幫你 transform prisma client queries 到你的 DataBase 透過 TCP 連線, 這部分 prisma 已經幫你處理好了,無需再做額外的設定,這也是 prisma 預設的 driver 叫做 Preview。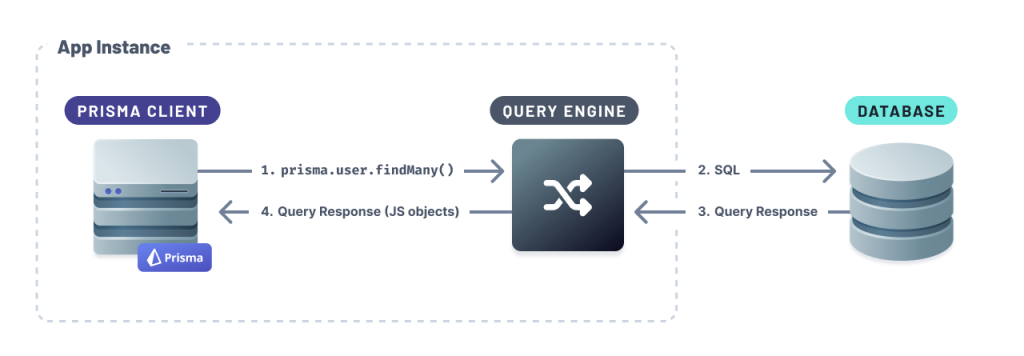
圖片來源
其中如果需要其他 DB driver 就會再套一層 Database Driver ,在這邊 prisma client 會透過 Query Engine 幫你轉成 SQL 語句,然後這些生成的 SQL 語句會透過 JavaScript database driver 幫你執行到 DataBase。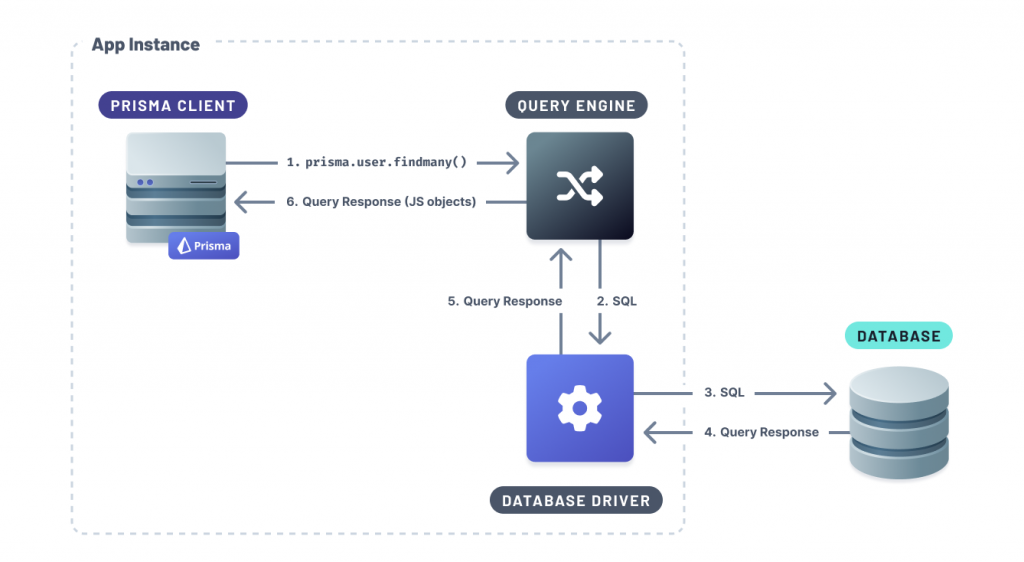
圖片來源
簡單來說如果你完全不需要用到其他 DB 的 adapter ,那這邊的 dirver 不用去設定
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
但如果需要用到例如 pg 的情況去控制你的 connect pool 就需要加上 adapter 否則 prisma 無法兼容。
import { Pool } from 'pg'
import { PrismaPg } from '@prisma/adapter-pg'
import { PrismaClient } from '@prisma/client'
const connectionString = `${process.env.DATABASE_URL}`
const pool = new Pool({ connectionString })
const adapter = new PrismaPg(pool)
const prisma = new PrismaClient({ adapter })
const main = async () => {
const data = await prisma.users.findMany({})
console.log(data)
}
Database drivers 說白了就是一層讓 prisma client 可以跟你 db 的 driver 溝通的媒介,這也是因為我們的 application 會根據不同環境,例如你可能會是 serverless 所以會用到 Neon 等等透過 https 方式操作 DB,使用到的 DB driver 也不相同,prisma 就是為了兼容所以才有 Database drivers adapter 的出現。
這邊簡單示範一下 postgres 以及 node-postgres 當作範例,因為 node-postgres 算是目前 js 生態中最常見的 driver。
首先先指定 datasource 的 provider 是 postgresql
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
然後在你的 .env 中加上 DATABASE_URL 這個 env
// .env
DATABASE_URL="YOUR_CONNECT_URL"
之後我們修之後我們修改一下 previewFeatures 是 driverAdapters ,prisma 預設是使用 Preview 。
// schema.prisma
generator client {
provider = "prisma-client-js"
previewFeatures = ["driverAdapters"]
}
之後 generate prisma client ,如此你的 prisma 就成功與你的 DB driver 開啟通道了~
>npx prisma generate
接著 install 相關的 lib
>npm install pg
>npm install @prisma/adapter-pg
>npm install --save-dev @types/pg
然後 create 一個 prisma client instance ,這邊要記得使用 adapter 否則上面 adpater 的設定就沒意義了XD
import { Pool } from 'pg'
import { PrismaPg } from '@prisma/adapter-pg'
import { PrismaClient } from '@prisma/client'
const connectionString = `${process.env.DATABASE_URL}`
const pool = new Pool({ connectionString })
const adapter = new PrismaPg(pool)
const prisma = new PrismaClient({ adapter })
補充一個 prisma adapter 提供一個 schema 功能這部分我們明天再仔細說明跟實作。
const adapter = new PrismaPg(pool, {
schema: 'myPostgresSchema'
})
prisma 的 connect URL 是完全遵守 postgresql 官方的 guideline,有興趣的讀者可以再細看下去~
postgresql://USER:PASSWORD@HOST:PORT/DATABASE
大致上的內容如下
| Name | Placeholder | Description |
|---|---|---|
| HOST | HOST | DB 域名 |
| Port | Port | 你的 db 在哪個 port 執行 |
| User | User | Database user name |
| Password | Password | Database user password |
| Database | Database | Database 名稱 |
另外一個有趣的地方是,除了上方基本的 URL 組成外,還可以額外添加 Arguments 透過 key & value 方式串連如下:
postgresql://USER:PASSWORD@HOST:PORT/DATABASE?KEY1=VALUE&KEY2=VALUE&KEY3=VALUE
這邊簡單舉一個例子,假設我需要用到 schema 的功能名稱叫做 myschema ,以及我需要控制 connection pool size 是 5 並且 3 秒後就 timeout URL 會長成如下 :
postgresql://USER:PASSWORD@HOST:PORT/DATABASE?schema=myschema&connection_limit=5&socket_timeout=3
其實還有很多內容,例如 SSL 憑證獲釋 socket 的配置,這些礙於篇幅所以就不更細得說明,有興趣的讀者可以再研究研究~
延伸閱讀
最後補充一個 cache 小知識,在 postgrest 中有一個東西叫做 A prepared statement ,主要目的是優化 SQL 在 compiled 重複 query 語法的,如果同樣的 SQL 指令,不會因為執行次數,又額外再去 compiled 。
那 prisma 也做了一樣的優化就是在 query engine 中也做了一樣的事情,如此也可以減少 database CPU 的使用量,以及 query 的 latency 。
舉個例子假設有以下兩個 query :
SELECT * FROM user WHERE name = "John";
SELECT * FROM user WHERE name = "Brenda";
以上兩者的 query 其實是一樣的,會被 A prepared statement 參數化成以下的 query ,如此一來第二次的 query 就會跳過 SQL 的準備階段,直接返回你要的 result。
SELECT * FROM user WHERE name = $1
prisma 對於每個 connect 都會隔離彼此的 cache for storing prepared statements ,如果你需要調整 cache size 的話,只需要加上 statement_cache_size 這個參數,到你的 connect URL 就可以,預設是 500 個 statements 。
那如果你不希望有 cache 的話只需要加上 pgbouncer 設成 true 就可以了~
postgresql://USER:PASSWORD@HOST:PORT/DATABASE?pgbouncer=true
今天內容大致到這邊,明天先補充一下 postgresql 中 schema 的概念~
✅ 前端社群 :
https://lihi3.cc/kBe0Y

